Introduction
META’s recent release of Segment Anything 2 (SAM2) as a fully open-source project, where both the code and the models are open-source, opens the door for many interesting use cases. One use case is people detection and tracking.
Suppose, for example, that I wanted to detect and track if people enter some region in my camera’s view. The YOLO toolset has been widely used for people detection, and here we use it to detect people whose YOLO-created bounding box intersects with a chosen detection region. Then we use points around the center of that bounding box as seeds for tracking those individuals with SAM2.
Warning
This code is shared purely for research purposes and should not be used as-is for anything beyond education. The reliability of these tools in production settings needs to be tested thoroughly
Code
Code for this post can be found here.
Procedure
- Create synthetic camera footage with Runway ML Gen 3
- Pick a frame early in the synthetic footage, in this case, frame 30
- Designate a detection region in the image
- Get people detection bounding boxes from the image
- Get a subset of detection bounding boxes which intersect with the detection region
- Get the center point of the detection bounding boxes in that subset, and use those as seeds for SAM2 to track those individuals through the remainder of the video
Setup
First, we need to set up the environment and install the required packages:
Tip
The pinning of package versions here is to help ensure that this code can work as is out-of-the-box; however, you may get better results by unpinning these versions and just using the latest code. It is generally best practice to pin packages in production environments.
| |
Loading and Processing the Video
We start by converting the input video into frames. The frames will be processed to detect and segment people.
Info
As of the publication of this post, SAM2 only supports JPEG.
First we do some initial setup:
| |
Next we extract jpg frames from the mp4 video we uploaded to the videos folder:
| |
Finally, we put all the frame file paths in a list for later processing:
| |
People Detection and Segmentation
Detecting people with YOLO
Using YOLO, we detect people in the frames and highlight those whose bounding boxes fall within a designated red zone.
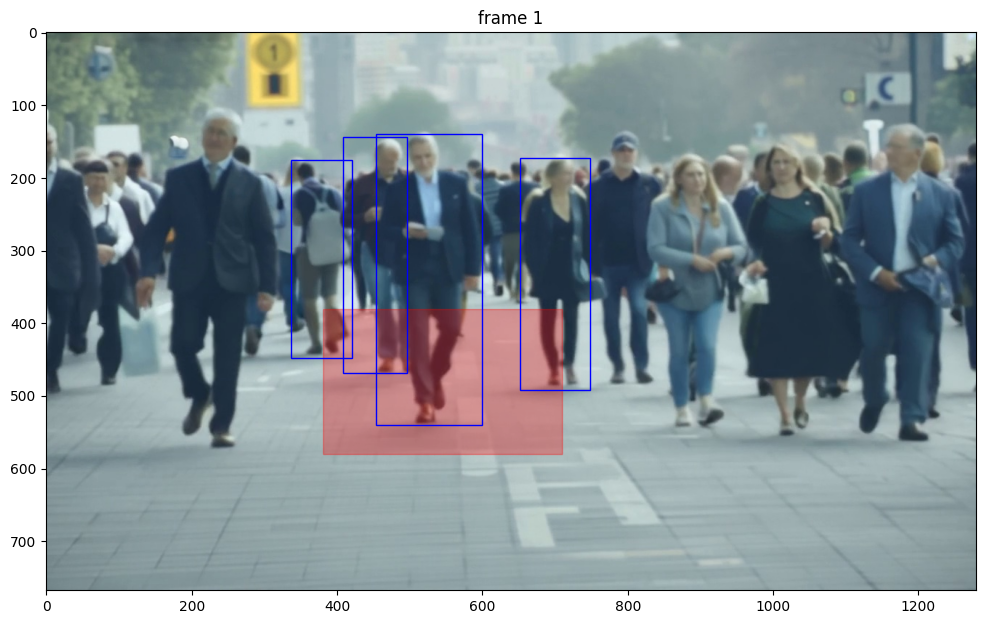
We pick which frame to detect in and set an image_path variable:
| |
Next we add a function to plot the detection region:
| |
Now we perform the people detections:
Warning
We are using YOLOv5 here, but there are newer version available.
| |
Initializing the Segment Anything 2 Predictor
We initialize the SAM2 predictor to generate masks for each detected person as follows.
Note
You’ll notice that in addition to using the point of center of the bounding boxes, we use two more points slightly above it. This is done to improve the SAM2 detection results. The YOLO bounding box center is typically around the midsection of a detected individual, so selecting a few points above helps ensure we target the whole individual more reliably with SAM2.
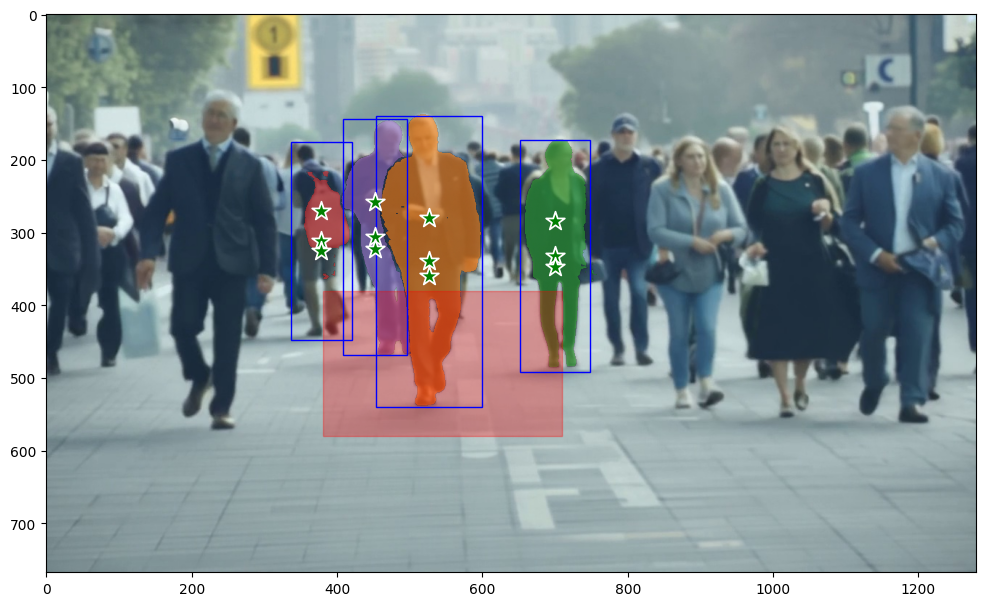
We use some functions to help us with plotting and DRYing up some detections. These first two functions come directly from SAM2’s example notebook:
| |
We also have a few helper functions to make our code DRY/cleaner:
| |
This is the important loop that applies SAM2 to the detected individuals:
| |
Propagating SAM2 Detections Forward Throughout the Video
We propagate the masks generated in the first frame through the entire video.
Note
The way we are doing this here is not efficient as we are propagating one detected person at a time, and then applying the masks later to the final image. This was done because detecting multiple people at once was showing some unwanted artifacts. In a future iteration of this, we will try to do the propegation for all detected points at the same time rather than via loops.
| |
We save the output frames as PNG for better quality (though at a cost of more disk space):
| |
Generating the Output Video
Finally, we compile the processed frames into an output video.
| |
The resulting video demonstrates how SAM2 maintains distinct object tracking throughout the video duration:
Note how the occlusion of the person masked in green by the person masked in orange does not cause the loss of tracking for the person masked in green. Even more impressive, the person masked in red is not lost by SAM2 despite being heavily occluded.
Conclusions
We demonstrated a way to detect and track people seen passing through a designated detection region in a video using YOLO to bootstrap SAM2. Next steps include:
- Cleaning up the code, de-looping the detection (see note in the SAM2 process section)
- Dockerizing this process
- Exploring monocular depth estimation as a way to more accurately detect proximity:
- Monocular depth estimation uses trained models that can pick up lighting cues to recreate the information related to the z axis in 2D video.
- In a subset of cases (perhaps even the majority of cases?), this recreation of z-axis depth perception is accurate enough to provide reliable detection of proximity in all three dimensions of space.
- Monocular depth estimation is being studied, for example, by Toyota in regards to autonomous vehicle driving. Further, the related field of Gaussian Splat is a very active area of research.